CBC 位翻转攻击
⊕
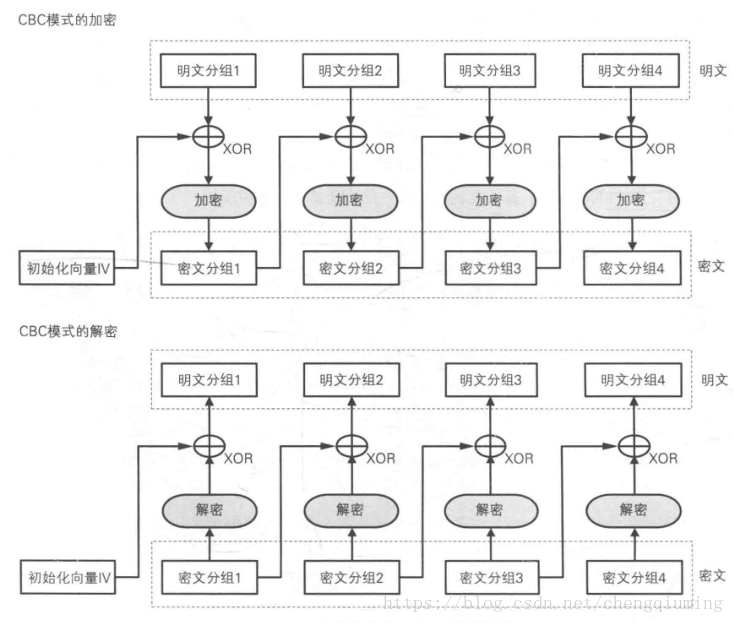
CBC加密解密过程:
1、核心思想
CBC的位翻转攻击通过对初始向量(IV)的优化,使得解密之后的明文块发生需要的变化,在CBC模式中密文的分组第一块通常为IV本身,我们需要考虑的是密文分组2的解密,明文分组1之后开始才是FLAG字段。
根据例题:https://aes.cryptohack.org/flipping_cookie/get_cookie/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| from Crypto.Cipher import AES
import os
from Crypto.Util.Padding import pad, unpad
from datetime import datetime, timedelta
KEY = ?
FLAG = ?
@chal.route('/flipping_cookie/check_admin/<cookie>/<iv>/')
def check_admin(cookie, iv):
cookie = bytes.fromhex(cookie)
iv = bytes.fromhex(iv)
try:
cipher = AES.new(KEY, AES.MODE_CBC, iv)
decrypted = cipher.decrypt(cookie)
unpadded = unpad(decrypted, 16)
except ValueError as e:
return {"error": str(e)}
if b"admin=True" in unpadded.split(b";"):
return {"flag": FLAG}
else:
return {"error": "Only admin can read the flag"}
@chal.route('/flipping_cookie/get_cookie/')
def get_cookie():
expires_at = (datetime.today() + timedelta(days=1)).strftime("%s")
cookie = f"admin=False;expiry={expires_at}".encode()
iv = os.urandom(16)
padded = pad(cookie, 16)
cipher = AES.new(KEY, AES.MODE_CBC, iv)
encrypted = cipher.encrypt(padded)
ciphertext = iv.hex() + encrypted.hex()
return {"cookie": ciphertext}
|
iv为一个任意的16字节字段,其定义了每个块的大小也都为16字节,而cookie的前16个字符便为明文分组2的内容
而在源代码中,明确指出当admin=False存在在cookie中的时候,是访问不到flag的,于是我们选择对初始向量进行优化
假设原明文分组2为 a1
a1 = 密文分组1 XOR IV
假设需要的明文分组2为a2
a2 = 密文分组1 XOR IV XOR a1 XOR a2
所以新的IV就为
New_IV = IV ^ a1 ^ a2
得到翻转后的New_IV 位翻转成功!!!!!
其余正常操作即可!!!!!!!!!
总结
CBC位翻转攻击的核心主要就是对初始向量的优化,将明文第一块变成自己想要的值,以下位wp,博主在后续会优化对代码的注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| import requests
from Crypto.Util.number import *
result = requests.get('https://aes.cryptohack.org/flipping_cookie/get_cookie/')
ciphertext = result.json()["cookie"]
ciphertext = bytes.fromhex(ciphertext)
c1 = hex(bytes_to_long(ciphertext[0:16]))[2:]
c2 = hex(bytes_to_long(ciphertext[16:32]))[2:]
c3 = hex(bytes_to_long(ciphertext[32:48]))[2:]
cookie = c2 + c3
a1 = b'admin=False;expi'
a2 = b'admin=True;00000'
k1 = bytes_to_long(a1)
k2 = bytes_to_long(a2)
m1 = hex(k1)
m2 = hex(k2)
IV_new = int(m1, 16) ^ int(m2, 16) ^ int(c1 , 16)
IV_new = hex(IV_new)[2:]
print(IV_new)
result2 = requests.get(f'http://aes.cryptohack.org/flipping_cookie/check_admin/{cookie}/{IV_new}')
l = result2.json()
print(l)
|
在最近的做题过程中,发现之前爬虫学的一部分知识最近有在反复用到
request.get()以这一段代码来获取网页内容,之后再用json格式读取需要的内容
